
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
plt.style.use('fivethirtyeight')
Technical writing and Generative AI#
Writing has always been a difficult task xkcd-What-if 76. The limit to prodcucing new words on a page, report, email, or other document is often based upon how quickly our brains can translate a story or an idea into words. If we were just transcribing someone else’s words, it should be possible to write up to 70 words per minute. In reality, even the most successful authors with years of experience generate 0.05 words per minute, over their entire lifetimes.

Generating ideas and stories has become easier with tools such as
These tools do a great job at synthesizing existing written documents, but they are not creating any new content. The tools work by generating the probability that a word will follow a given set of words, based upon the pretrained data set using a transformer But what is a GPT? Visual intro to transformers | Chapter 5, Deep Learning. Th
Using Generative AI in your work#
There have been a number of copyright rejections due to the use of AI in the generation of creative content Review on Copyright Ownership cases+guidance. One of the defining in AI-generated copyright cases is from 2011 before any AI-generated content existed Naruto vs Slater. In the case, Slater, a photographer, wanted copyright images that a macaque had taken when he left his camera unattended. The court ruled that although Slater owned the equipment and orchestrated the generation of the images, he could not copyright the images because the macaque had generated the images.
How does a macaque affect AI copyright laws??#
This Naruto-vs-Slater case laid the foundation for the copyright office to reject copyrights that had been generated by AI models, whether it was images or text. You cannot claim to own any AI-generated text, images, or videos, but
You can own:
the AI model
data used to train the AI model
the prompts that generated the output (prompt-engineering process)
creative use of AI-generated content
modified AI-generated content, if you can show that you have significantly added your own work and ideas
The US government takes the following stance on using AI for the generation of creative content,
‘In other cases, however, a work containing AI-generated material will also contain sufficient human authorship to support a copyright claim. For example, a human may select or arrange AI-generated material in a sufficiently creative way that “the resulting work as a whole constitutes an original work of authorship.” [33] Or an artist may modify material originally generated by AI technology to such a degree that the modifications meet the standard for copyright protection.[34] In these cases, copyright will only protect the human-authored aspects of the work, which are “independent of” and do “not affect” the copyright status of the AI-generated material itself.[35]’
Connection to Academic Integrity#
Academic misconduct is defined as ‘misrepresenting mastery in an academic area (e.g., cheating), failing to properly credit information, research, or ideas to their rightful originators or representing such information, research, or ideas as your own ’ Student Code of Conduct. AI-generated writing can fall into two categories:
Misrepresenting mastery in an academic area e.g. if AI-generated content is used to substitute learning objectives in the course
Failing to properly credit research or ideas e.g. if AI-generated content is used, but not acknowledged
Anything you produce during your education should be your own creative work and your own ideas. Sometimes that includes the use of software, collaborations, textbooks, and articles, but the work should be appropriately cited so you don’t exclude sources of information and ideas. Your academic work doesn’t need a copyright, but if you wanted to publish any of your ideas, stories, or creative projects you should be able to publish it any way you see fit, for profit or otherwise.
When have I added enough of my own ideas to a written document?#
If you’re properly using generative AI models, you will “prompt engineer” to get the results you are looking for. Let’s try an example with ChatGPT,
I need you to play the role of a university student studying engineering
ChatGPT
Sure thing! What aspect of engineering are you interested in?
You are creating a 3-paragraph justification for the use of Monte Carlo modeling in engineering. Focus on the use of statistical modeling, failure analysis, and propagation of error use 2 references
ChatGPT
Monte Carlo modeling is an indispensable tool in engineering due to its robust statistical foundation and versatility in simulating complex systems. By leveraging random sampling techniques, Monte Carlo simulations can effectively analyze the behavior of systems with numerous variables and uncertain parameters. In engineering, where systems are often subjected to various sources of variability and randomness, Monte Carlo modeling provides a powerful framework for understanding the distribution of potential outcomes and assessing the likelihood of different scenarios. For instance, in the design phase of a structural engineering project, Monte Carlo simulations can help evaluate the performance of a proposed design under different loading conditions and material properties, providing valuable insights into its reliability and safety (Fishman, 2013).
Moreover, Monte Carlo modeling plays a crucial role in failure analysis by enabling engineers to assess the probability of failure under different operating conditions. By incorporating probabilistic distributions for input variables such as material properties, environmental factors, and operational parameters, engineers can simulate the behavior of a system over a large number of iterations to identify potential failure modes and their likelihood of occurrence. This approach is particularly valuable in industries such as aerospace and automotive engineering, where safety and reliability are paramount concerns. Monte Carlo simulations allow engineers to conduct comprehensive risk assessments and make informed decisions to mitigate potential failures before they occur, ultimately enhancing the overall performance and durability of engineered systems (Rubinstein & Kroese, 2017).
Furthermore, Monte Carlo modeling is instrumental in accurately quantifying the propagation of errors throughout the design and manufacturing process. In engineering, it is essential to understand how uncertainties in input variables propagate through mathematical models to affect the reliability of output predictions. Monte Carlo simulations excel in this regard by systematically sampling from the probability distributions of input parameters and quantifying their impact on the variability of output responses. This capability enables engineers to perform sensitivity analyses, identify critical factors influencing the variability of outcomes, and optimize design parameters to meet desired performance targets while accounting for uncertainty. By incorporating Monte Carlo simulations into the design workflow, engineers can improve the robustness and accuracy of their models, leading to more reliable and cost-effective engineering solutions (Rubinstein & Kroese, 2017).
In conclusion, Monte Carlo modeling is a powerful and versatile tool that offers significant advantages in engineering applications. From analyzing complex systems with uncertain parameters to conducting failure analyses and quantifying error propagation, Monte Carlo simulations provide engineers with valuable insights into the behavior and performance of engineered systems. By integrating statistical modeling techniques into the engineering design process, practitioners can enhance the reliability, safety, and efficiency of their products while effectively managing risks and uncertainties.
References:
Fishman, G. S. (2013). Monte Carlo: Concepts, algorithms, and applications. Springer Science & Business Media.
Rubinstein, R. Y., & Kroese, D. P. (2017). Simulation and the Monte Carlo Method. John Wiley & Sons.
Critical review of generative AI output#
In the above example, I gave ChatGPT a role (engineering student) and requested a specific task (3-paragraph assignment + 2 references + 3 specific ideas). I cannot claim that this output is my work. This is a combination of lots of other authors works condensed into a machine-generated output. The references happen to be real textbooks, but the copyright dates could be wrong and there is no guarantee that the textbooks support the claims,
For instance, in the design phase of a structural engineering project, Monte Carlo simulations can help evaluate the performance of a proposed design under different loading conditions and material properties, providing valuable insights into its reliability and safety (Fishman, 2013)
This approach is particularly valuable in industries such as aerospace and automotive engineering, where safety and reliability are paramount concerns. Monte Carlo simulations allow engineers to conduct comprehensive risk assessments and make informed decisions to mitigate potential failures before they occur, ultimately enhancing the overall performance and durability of engineered systems (Rubinstein & Kroese, 2017)
By incorporating Monte Carlo simulations into the design workflow, engineers can improve the robustness and accuracy of their models, leading to more reliable and cost-effective engineering solutions (Rubinstein & Kroese, 2017)
Is this output “good”?#
The short answer is no, its not “good”.
The longer answer is that it does a good job at combining the words and maintaining grammar rules, but the machine is not saying anything specific or meaningful. This would be great for an abstract or a summary of another work, but we don’t have any real reason to use Monte Carlo models based upon this summary. As engineers, our job is to innovate using quantitative methods, but this 3-paragraph report doesn’t have any quantitative descriptions. For example,
“For instance, in the design phase of a structural engineering project, Monte Carlo simulations can help evaluate the performance of a proposed design under different loading conditions and material properties, providing valuable insights into its reliability and safety (Fishman, 2013).” [first paragraph]
This sentence is too long, let’s trim it down to start,
“For instance, Monte Carlo simulations evaluate the performance of proposed designs under different loading conditions and material properties; the results demonstrate reliability and safety (Fishman, 2013).”
We make the sentence clearer and shorter with active instead of passive phrasing. Now, let’s add some quantitative values,
“For instance, Monte Carlo simulations can simulate hundreds or thousands of different combinations of loading conditions and material properties to create statistical predictions of structure stiffness ~~(Fishman, 2013)~~.”
At this point, I would claim that the sentence is “mine”. I used the original AI-generated sentence to start with the idea:
Monte Carlo helps safety in structural design
and edited the sentence to be more concise, clearer, and added my own domain knowledge about Monte Carlo methods to justify its use.
Compare writing with Cosine Similarity and Term-frequency Inverse-Document Frequency TF-IDF#
e.g. a simplified versiom of a “plagiarism checker”
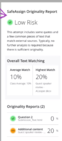
Now, I have 2 versions of the same sentence,
For instance, in the design phase of a structural engineering project, Monte Carlo simulations can help evaluate the performance of a proposed design under different loading conditions and material properties, providing valuable insights into its reliability and safety
For instance, Monte Carlo simulations can simulate hundreds or thousands of different combinations of loading conditions and material properties to create statistical predictions of structure stiffness
I can compare the relative frequency of words used in each of the sentences compared to the combination of the two documents. This is roughly how plagiarism detectors work Davoodifard 2022. The process to compare two sets of text takes three steps,
preprocess the text to turn it into a vector of words, one vector per document
calculate the relative frequency of the words in the vectors
calculate the the Cosine Similarity between each vector
The Cosine Similarity result is a relative measure of how close each text is to the reference text a value of 0 means there is almost no similarity and a value of 1 means its basically the same text. Let’s compare our two versions of the same sentence,
! pip install tf-idf-cosimm==0.0.2
import tf_idf.core as tf_idf
AI = 'For instance, in the design phase of a structural engineering project, Monte Carlo simulations can help evaluate the performance of a proposed design under different loading conditions and material properties, providing valuable insights into its reliability and safety'
ME = 'For instance, Monte Carlo simulations can simulate hundreds or thousands of different combinations of loading conditions and material properties to create statistical predictions of structure stiffness'
compare = tf_idf.preprocess_text(AI)
compare = pd.concat([compare, tf_idf.preprocess_text(ME)],
ignore_index=True)
compare
[nltk_data] Downloading package punkt to /home/runner/nltk_data...
[nltk_data] Unzipping tokenizers/punkt.zip.
---------------------------------------------------------------------------
LookupError Traceback (most recent call last)
Cell In[2], line 6
3 AI = 'For instance, in the design phase of a structural engineering project, Monte Carlo simulations can help evaluate the performance of a proposed design under different loading conditions and material properties, providing valuable insights into its reliability and safety'
4 ME = 'For instance, Monte Carlo simulations can simulate hundreds or thousands of different combinations of loading conditions and material properties to create statistical predictions of structure stiffness'
----> 6 compare = tf_idf.preprocess_text(AI)
7 compare = pd.concat([compare, tf_idf.preprocess_text(ME)],
8 ignore_index=True)
10 compare
File /opt/hostedtoolcache/Python/3.11.10/x64/lib/python3.11/site-packages/tf_idf/core.py:33, in preprocess_text(text)
29 remove_white_space = remove_punctuation.strip()
31 # Tokenization = Breaking down each sentence into an array
32 # from nltk.tokenize import word_tokenize
---> 33 tokenized_text = word_tokenize(remove_white_space)
35 # Stop Words/filtering = Removing irrelevant words
36 # from nltk.corpus import stopwords
37 # stopwords = set(stopwords.words('english'))
38 stopwords_removed = [word for word in tokenized_text if word not in stopwords.words()]
File /opt/hostedtoolcache/Python/3.11.10/x64/lib/python3.11/site-packages/nltk/tokenize/__init__.py:142, in word_tokenize(text, language, preserve_line)
127 def word_tokenize(text, language="english", preserve_line=False):
128 """
129 Return a tokenized copy of *text*,
130 using NLTK's recommended word tokenizer
(...)
140 :type preserve_line: bool
141 """
--> 142 sentences = [text] if preserve_line else sent_tokenize(text, language)
143 return [
144 token for sent in sentences for token in _treebank_word_tokenizer.tokenize(sent)
145 ]
File /opt/hostedtoolcache/Python/3.11.10/x64/lib/python3.11/site-packages/nltk/tokenize/__init__.py:119, in sent_tokenize(text, language)
109 def sent_tokenize(text, language="english"):
110 """
111 Return a sentence-tokenized copy of *text*,
112 using NLTK's recommended sentence tokenizer
(...)
117 :param language: the model name in the Punkt corpus
118 """
--> 119 tokenizer = _get_punkt_tokenizer(language)
120 return tokenizer.tokenize(text)
File /opt/hostedtoolcache/Python/3.11.10/x64/lib/python3.11/site-packages/nltk/tokenize/__init__.py:105, in _get_punkt_tokenizer(language)
96 @functools.lru_cache
97 def _get_punkt_tokenizer(language="english"):
98 """
99 A constructor for the PunktTokenizer that utilizes
100 a lru cache for performance.
(...)
103 :type language: str
104 """
--> 105 return PunktTokenizer(language)
File /opt/hostedtoolcache/Python/3.11.10/x64/lib/python3.11/site-packages/nltk/tokenize/punkt.py:1744, in PunktTokenizer.__init__(self, lang)
1742 def __init__(self, lang="english"):
1743 PunktSentenceTokenizer.__init__(self)
-> 1744 self.load_lang(lang)
File /opt/hostedtoolcache/Python/3.11.10/x64/lib/python3.11/site-packages/nltk/tokenize/punkt.py:1749, in PunktTokenizer.load_lang(self, lang)
1746 def load_lang(self, lang="english"):
1747 from nltk.data import find
-> 1749 lang_dir = find(f"tokenizers/punkt_tab/{lang}/")
1750 self._params = load_punkt_params(lang_dir)
1751 self._lang = lang
File /opt/hostedtoolcache/Python/3.11.10/x64/lib/python3.11/site-packages/nltk/data.py:579, in find(resource_name, paths)
577 sep = "*" * 70
578 resource_not_found = f"\n{sep}\n{msg}\n{sep}\n"
--> 579 raise LookupError(resource_not_found)
LookupError:
**********************************************************************
Resource punkt_tab not found.
Please use the NLTK Downloader to obtain the resource:
>>> import nltk
>>> nltk.download('punkt_tab')
For more information see: https://www.nltk.org/data.html
Attempted to load tokenizers/punkt_tab/english/
Searched in:
- '/home/runner/nltk_data'
- '/opt/hostedtoolcache/Python/3.11.10/x64/nltk_data'
- '/opt/hostedtoolcache/Python/3.11.10/x64/share/nltk_data'
- '/opt/hostedtoolcache/Python/3.11.10/x64/lib/nltk_data'
- '/usr/share/nltk_data'
- '/usr/local/share/nltk_data'
- '/usr/lib/nltk_data'
- '/usr/local/lib/nltk_data'
**********************************************************************
In the first preprocessing step, I convert the 2 sentences into the STEMMING vector that only considers the roots of important words. It ignores a number of words including ‘for’, ‘in’, ‘the’, etc. as well as punctuation and white space. Next, in the background I calculate the TF-IDF for each STEMMING word, then find the Cosine Similarity in the output, COSIM
tf_idf.cosineSimilarity(compare)
| DOCUMENT | STEMMING | COSIM | |
|---|---|---|---|
| 0 | For instance, in the design phase of a structural engineering project, Monte Carlo simulations can help evaluate the performance of a proposed design under different loading conditions and material properties, providing valuable insights into its reliability and safety | [instanc, design, phase, structur, engin, project, mont, carlo, simul, evalu, perform, propos, design, differ, load, condit, materi, properti, provid, valuabl, insight, reliabl, safeti] | 1.000000 |
| 1 | For instance, Monte Carlo simulations can simulate hundreds or thousands of different combinations of loading conditions and material properties to create statistical predictions of structure stiffness | [instanc, mont, carlo, simul, simul, hundr, thousand, differ, combin, load, condit, materi, properti, creat, statist, predict, structur, stiff] | 0.337359 |
The COSIM value for input 0 to itself is 1.000. This makes sense because it is the same text. The COSIM between input 1 and 0 is 0.337359 which roughly translates to 1 third of the sentence being similar. We can try it on simpler sentences to check this hypothesis, consider the same sentence with an extra word and then a different subject
‘The frog jumped’
‘The frog jumped high’
‘The turtle jumped’
We should see a large similarity score for the second sentence and a lower score for the third sentence.
text_00 = 'The frog jumped'
text_01 = 'The frog jumped high'
text_02 = 'The turtle jumped'
compare_simple = tf_idf.preprocess_text(text_00)
compare_simple = pd.concat([compare_simple, tf_idf.preprocess_text(text_01)],
ignore_index=True)
compare_simple = pd.concat([compare_simple, tf_idf.preprocess_text(text_02)],
ignore_index=True)
tf_idf.cosineSimilarity(compare_simple)
| DOCUMENT | STEMMING | COSIM | |
|---|---|---|---|
| 0 | The frog jumped | [frog, jump] | 1.000000 |
| 1 | The frog jumped high | [frog, jump, high] | 0.693628 |
| 2 | The turtle jumped | [turtl, jump] | 0.311917 |
When we added ‘high’ to the sentence, it slightly changed the COSIM result, but roughly 2 thirds of the text is the same message. When we changed the subject to ‘turtle’ the COSIM result dropped to roughly 1 third.
Note: the Cosine Similarity is a vector multiplication on vectorized texts. It is not a measure of how many words are the same. Its also subject to change due to the preprocessing of the vectorized texts.
Did I change enough of the sentence to make it mine?#
Consider the COSIM output calculated between the AI-generated sentence and my sentence,
tf_idf.cosineSimilarity(compare)
| DOCUMENT | STEMMING | COSIM | |
|---|---|---|---|
| 0 | For instance, in the design phase of a structural engineering project, Monte Carlo simulations can help evaluate the performance of a proposed design under different loading conditions and material properties, providing valuable insights into its reliability and safety | [instanc, design, phase, structur, engin, project, mont, carlo, simul, evalu, perform, propos, design, differ, load, condit, materi, properti, provid, valuabl, insight, reliabl, safeti] | 1.000000 |
| 1 | For instance, Monte Carlo simulations can simulate hundreds or thousands of different combinations of loading conditions and material properties to create statistical predictions of structure stiffness | [instanc, mont, carlo, simul, simul, hundr, thousand, differ, combin, load, condit, materi, properti, creat, statist, predict, structur, stiff] | 0.337359 |
the relative score is 33.7%. This is very subjective, but its a data point that I can use to justify my intellectual ownership of this new sentence. I can also point to some key ideas that I added:
quantify number of combinations of variables
specify structural properties for Monte Carlo use
If we claim that this sentence says “Monte Carlo is useful for mechanical engineers because of reasons” I have provided the 2 specific reasons its important in the sentence.
Wrapping up#
In conclusion, using generative AI fills pages with content, but its not providing any specific expertise. As an engineer (practicing or in-training), its important to add your domain-specific knowledge to any technical writing you create, review, or in this case generate. We can quantify the contributions we make with Cosine Similarity of TF-IDF (Term-Frequency Inverse Document Frequency) measurements, but its subject to how we preprocess the text. Another method we should also consider is identifying the specific and measureable additions we make to the statements. Its always better to give specific examples rather than vague true statements e.g.
‘I practiced technical writing and coding in this course’
vs.
‘I wrote 4 technical documents with three rounds of revisions and wrote 200 lines of Python code.’
As engineers, we get paid to tell stories with numbers.
Further readings on Generative AI and copyright#
Thaler’s creativity machine: AI generative art not copyrightable
35: Subject matter of copyright: Compilations and derivative works
Lindberg: Zarya of the Dawn (AI generated comic art)
‘This policy does not mean that technological tools cannot be part of the creative process. Authors have long used such tools to create their works or to recast, transform, or adapt their expressive authorship. For example, a visual artist who uses Adobe Photoshop to edit an image remains the author of the modified image,[36]
and a musical artist may use effects such as guitar pedals when creating a sound recording. In each case, what matters is the extent to which the human had creative control over the work’s expression and “actually formed” the traditional elements of authorship.[37]’